FREE | VST3+CLAP | 6.95MB
英文简介:
Format support
VST3: supports sample-accurate automation, but no note expressions.
CLAP: supports sample-accurate automation, supports threadpool, but no modulation (not regular and not polyphonic).
As you might have guessed from the above, it also doesn't do MIDI MPE.
Preset files (.ffpreset) are shareable between CLAP and VST3.
Resizing
It's fully resizable by scaling (by dragging the bottom right corner), but it does not react to OS DPI settings. That means, if you change your DPI settings, you'll have to resize manually. Just once, after that, the size is stored in a user settings file.
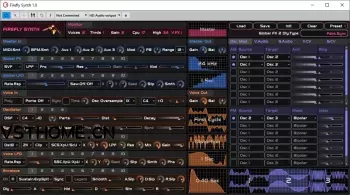
GUI
Right-click empty space for the undo/redo menu.
Right-click module number, matrix header, or first matrix column pops up various context menus to ease editing a bit.
Hover a parameter to see a more detailed description popup.
A knob with a circle in it or a slider with a small dot in it means it can be modulated by the CV matrices. These are exactly the parameters that should eventually (not supported yet) react to CLAP modulation. Nearly everything can be automated. Discrete valued parameters are automated per-block (global) or at-voice-start. Continuous-valued parameters are mostly sample-accurate.
MIDI
Supports Channel Pressure, Pitch Bend and all 128 CC parameters. You can access the MIDI signals through the CV routing matrices. MIDI note number and velocity are also available as modulation sources in the per-voice CV matrix.
Master module
MIDI and BPM smoothing parameters. BPM smoothing affects tempo-synced delay lines.
3 Auxilliary parameters to be used through the CV routing matrices and automation.
MIDI-linked modwheel and pitchbend (+ pitchbend range) parameters.
These react to external MIDI sources, have the UI updated etc. This also means they cannot be automated.
Voice control module
Oscillator oversampling factor
Portamento control with optional tempo sync
Voice pitch (note/cent) parameters affecting all oscillator base pitches
10 Per-voice DAHDSR envelopes
Optional tempo sync
Smoothing parameter
3 envelope modes and 4 slope modes (linear and 3 exponential types)
10 Per-voice and 10 global LFOs
Phase adjustment
Optional tempo sync
Smoothing parameter
Regular repeating or one-shot mode
Stair-stepping any periodic waveform
Optional 5 horizontal and 5 vertical skewing modes + corresponding control parameters
Various periodic waveforms + smooth noise, static noise and free-running static noise
See bottom of this document for shape and skew modes
4 Oscillators
Phased: anti-aliased DSF generator
Phased: anti-aliased basic generator with combined sine/saw/triangle/square+pwm
Random noise with seed and rate control (less = static, more = white noise) and built-in resonant filter
Extended Karplus-Strong with seed/rate/resonant filter for the initial excite stage and feedback and stretch parameters
Second Karplus-Strong mode which auto-adjusts the feedback according to a user-defined pitch ("midpoint") parameter
All generators can do unison with stereo spread parameter
Karplus-Strong can do unison with detune parameter
All generators can be source or target in the Osc Mod AM matrix, and source in the Osc Mod FM matrix
Phased generators can be target in the Osc Mod FM matrix
Phased generators can do unison with detune and phase offset parameter
Phased generators can hard-sync with adjustable cross-over time from unsynced to synced
AM, FM and hard sync are per-unison-voice.
If you modulate AM/FM, better to have equal unison voices between oscs.
Although it will work with unequal voice counts by remapping the voices.
Don't turn everything to the max.
With 8X oversampling + 8X unison plus 4X oscillator you will run [the equivalent of] 256 unison-voices
per synth voice and grind the cpu to a halt.
In fact better to design your sound so it doesn't need oversampling.
It's there for those very rare corner cases where it's both needed and makes a positive difference.
10 Per-voice and 10 global FX modules
Only global:
Reverb (Freeverb) with room size, damping, stereo spread, dry/wet and controllable allpass filter
Time or tempo-synced feedback delay with feedback amount, stereo-spread and dry/wet control and per-channel delay length
Time or tempo-synced multitap delay with tap amount, stereo-spread and dry/wet control, tap-count and initial hold parameter
Per-voice and global:
Comb filter with modulatable input and output gain and delay
State variable filter with various modes and frequency, resonance, keyboard-tracking and shelving gain control
Distortion module with 3 modes
Dry/wet and gain controls
Hard clip or "tanh" (soft clip)
Built-in resonant lowpass filter
Various periodic waveshaper functions + foldback distortion
Oversampling factor (here you might really need it if you go crazy)
Optional 5 before-shape (X) and 5 after-shape (Y) skewing modes + corresponding control parameters
See bottom of this document for shape and skew modes
The distortion modes affect where the filter is placed.
Mode A: filter is not used, schema is Input => Gain => SkewX => Shape => SkewY => Clip => Mix.
Mode B: filter before shape, schema is Input => Gain => SkewX => Filter => Shape => SkewY => Clip => Mix.
Mode C: filter after shape, schema is Input => Gain => SkewX => Shape => Filter => SkewY => Clip => Mix.
Like with the Osc section, don't turn everything up to the max. It will totally screw up the sound. Cool-but-not-noisy results can be had with a "smooth" shaper like sine-cosine-sine, a tanh clipper and playing around with the filter.
Osc Mod module
AM section:
AM (amplitude-modulate) stacking any oscillator
Ring control mixing AM/RM
Dry/wet (Amt) control mixing unmodulated/modulated
FM section:
FM (frequency-modulate) stacking any oscillator as source and basic/DSF oscillator as target
Modulation Index as defined in Chowning-style FM
Bipolar/unipolar mode (apparently bipolar is called "through-zero" sometimes)
In any case, bipolar may cause the target osc phase to travel "backwards", gives a nice distinct sound
Also see Osc section for interaction with oversampling and unison
Voice and Global Audio Matrix
Routing from Oscs to FXs to voice mixdown / final mixdown
Modulatable gain and stereo balancing
Note: you can only route FXs "upwards" e.g. 1->2 but not 2->1
Voice and Global CV Matrix
Global sources: Master section, Global LFO, MIDI
Voice sources: All global sources, plus: envelope, Voice LFO, Note-key, Note-velocity, and On-Note all global sources
Targets: lots!. Any continuous parameter of the Oscs, Fx's, Voice-In/Out sections, and global/voice Audio Matrices.
Min/Max: controls the modulation amount.
Op(erator): Multiply, Add, Add-Bipolar.
Subtypes absolute, relative (to modulation target) and stacked (relative to all previous operators).
If you don't want the modulation signal to clip, only use the "stacked" versions.
Shape and skew for distortion and LFO's
Shape modes:
Saw/sqr/tri/sin - I hope these are obvious.
SS, SC, CS, CC, SSS, SSC, ... etc => sine-sine, sine-cosine, cosine-sine, cosine-cosine, sine-sine-sine... etc
Fold (Distortion) => foldback shaper
Smooth (LFO) => this is a periodic smooth noise generator. Being periodic it can be phase-adjusted etc. It's a bit like Perlin noise.
Static, Static free-running (LFO): random forms with seed and step-count. Free-running will (for all practical purposes) never repeat.
Skew modes:
Off: does nothing. Very CPU efficient. So, use it instead of one of the other ones with skew factor set so it does nothing.
Lin: Linear skewing. Works well on saw/sqr/tri waves.
ScU/ScB: Scale Bi/Unipolar.
XpU/XpB: Exponential unipolar/bipolar skew. Works well with sine/cosine/sin-cos/cos-sin etc.
官网: https://github.com/sjoerdvankreel/firefly-synth






评论0